
語音轉文字的工具
下載Whisper
Whisper下載網址|https://github.com/Const-me/Whisper
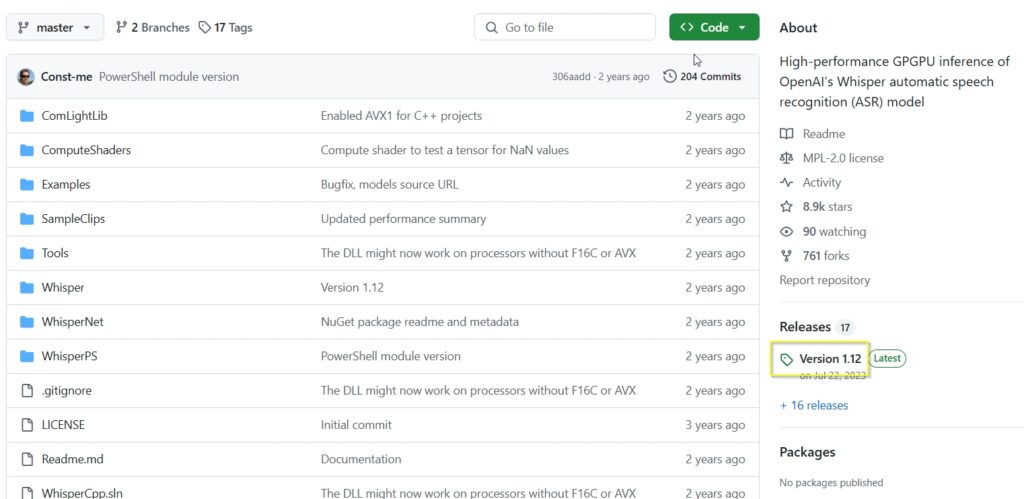
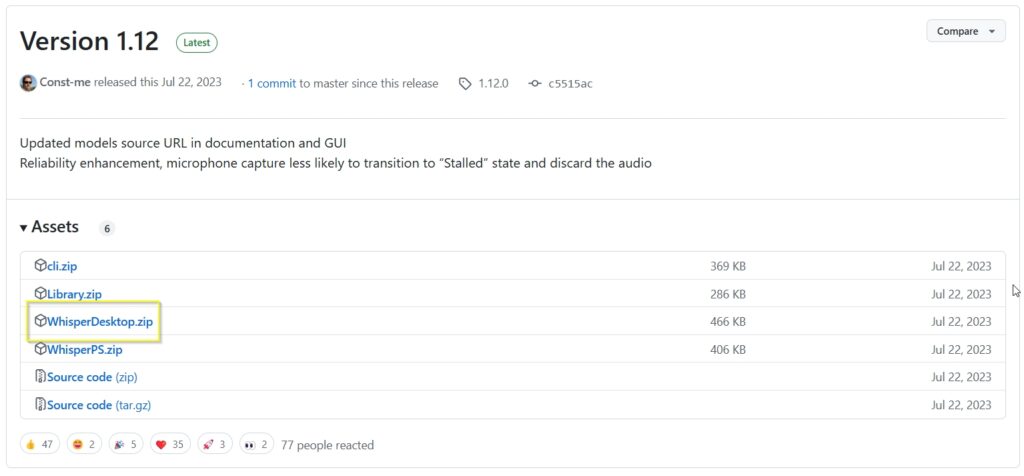
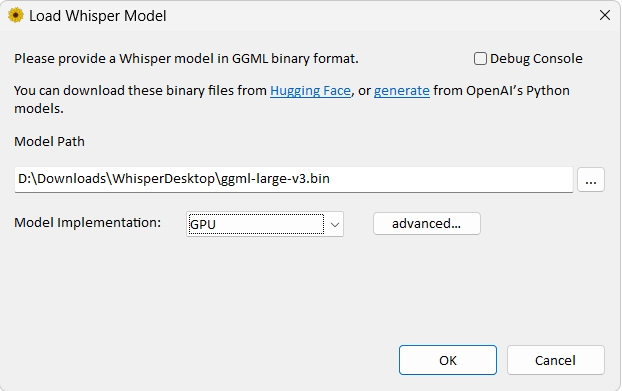
執行Whisper|下載並載入模型
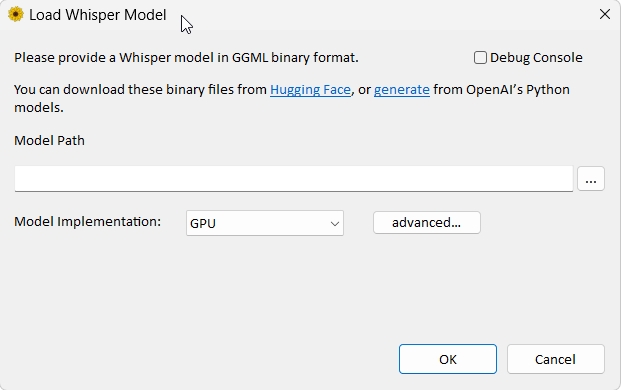

詢問了AI後,關於模型的選擇說明大概是:
1. 硬體性能
- 低階設備(手機、舊電腦):選擇 tiny 或 base,檔案小(75-142 MB),速度快,適合 CPU 或低記憶體環境。
- 中階設備(筆電、M1/M2 Mac):選 small(466 MB)或量化版(如 small-q5_1,181 MB),兼顧速度與品質。
- 高階設備(配 NVIDIA GPU 的桌機):用 medium(1.5 GB)或 large-v3(3.06 GB),支援 CUDA 加速,精度最高。
2. 語言需求
- 只轉英文:選 .en 版本(如 base.en),模型更小,專注英文辨識更準。
- 多語言(含中文):選無 .en 的版本(如 medium 或 large-v3),支援 100 多種語言,包括中文。
3. 用途與精度
- 快速測試或簡單語音:tiny 或 base,夠用且省資源。
- 會議記錄或清晰語音:small 或 medium,精度提升,錯誤率降低。
- 專業用途(播客、採訪):large-v3 或 large-v3-turbo,提供最佳辨識,尤其複雜環境或多語者。
4. 檔案大小與速度
- 量化版本(如 -q5_1、-q8_0):檔案小 30-50%,速度快,但細節略損,適合硬體有限時。
- 未量化版本(如 ggml-large.bin):完整精度,適合高品質需求。
執行Whisper|轉譯影音為字幕檔
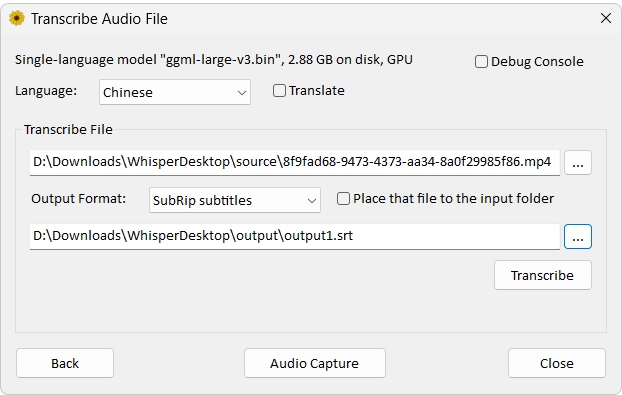
翻譯的速度還蠻快的,正確率也不錯!